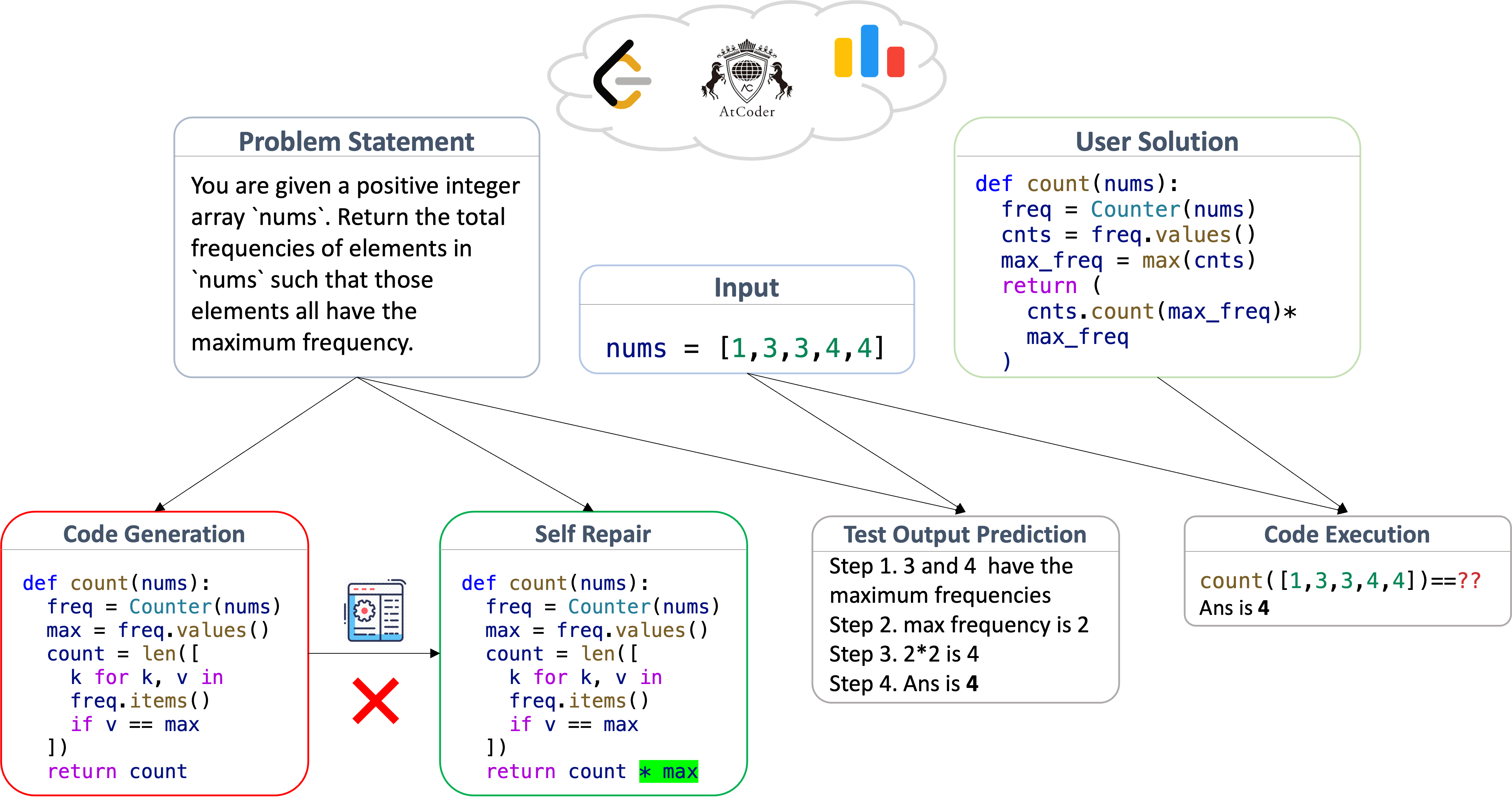
LiveCodeBench is a holistic and contamination-free evaluation benchmark of LLMs for code that continuously collects new problems over time. Particularly, LiveCodeBench also focuses on broader code-related capabilities, such as self-repair, code execution, and test output prediction, beyond mere code generation. Currently, LiveCodeBench hosts over three hundred high-quality coding problems published between May 2023 and February 2024. We evaluate 29 LLMs on LiveCodeBench scenarios and present novel empirical findings not revealed in prior benchmarks.
LiveCodeBench annotates problems with release dates, and thus allows evaluating models on problems released during a specific time period. Thus, for a newer model with a training-cutoff date D, we can evaluate it on problems released after D to measure its generalization on unseen problems.
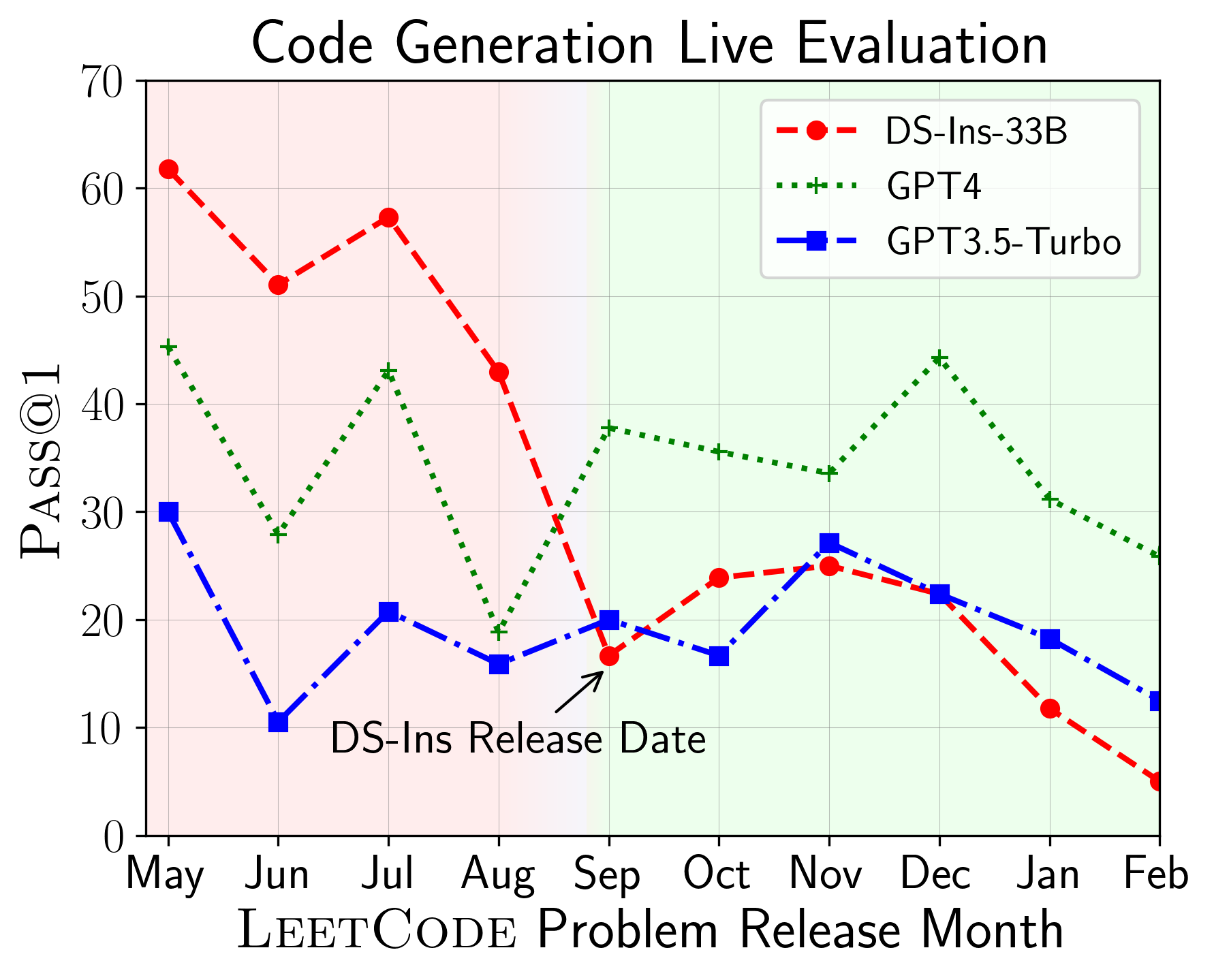
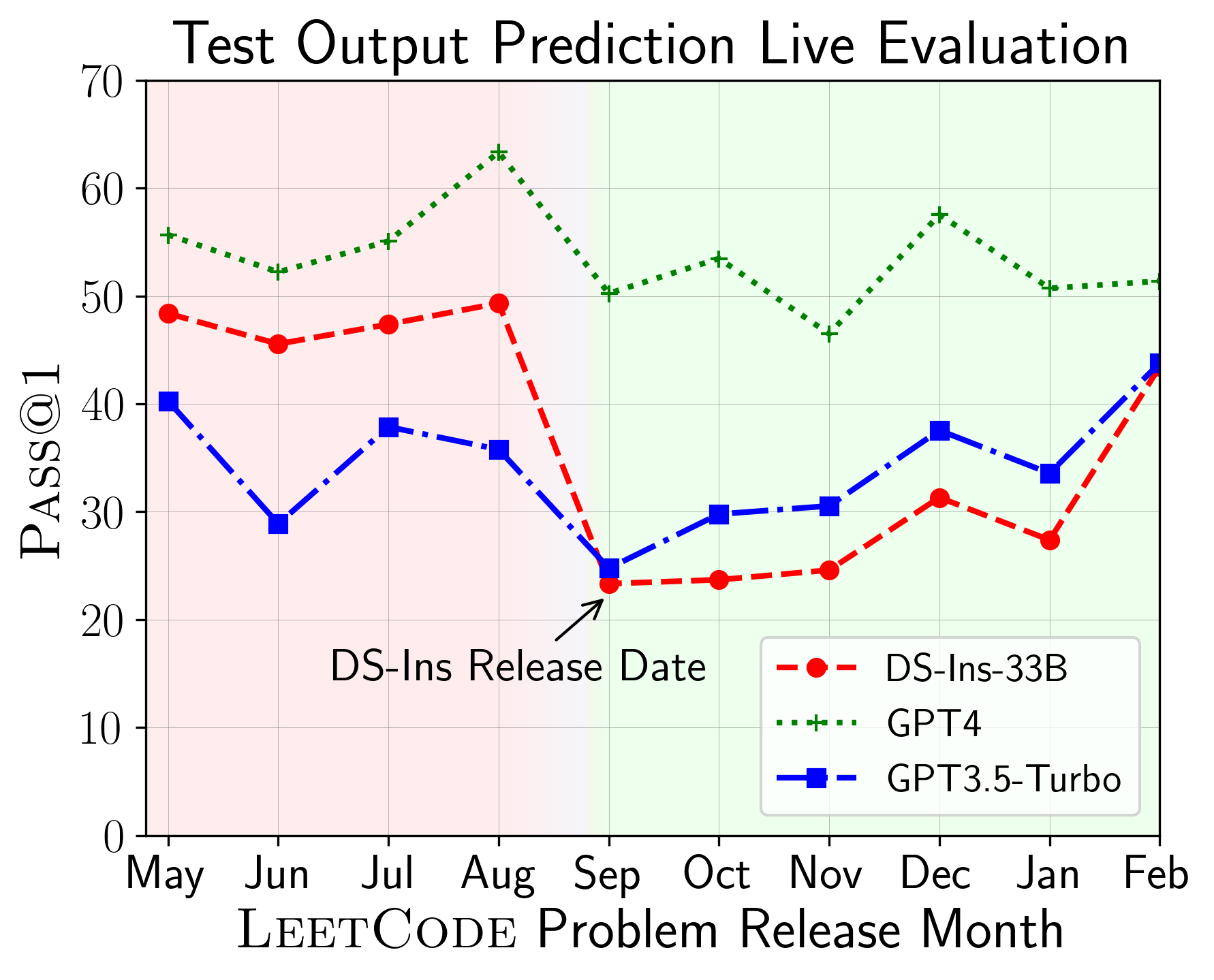
The above plots depict the performance of models on code generation and test output prediction scenarios on problems released over different months. We find that DeepSeek models exhibit a stark drop in performance on LeetCode problems released since September 2023, its release date, indicating that the earlier problems might be contaminated. In contrast, for GPT models, the performance is relatively stable across different months.
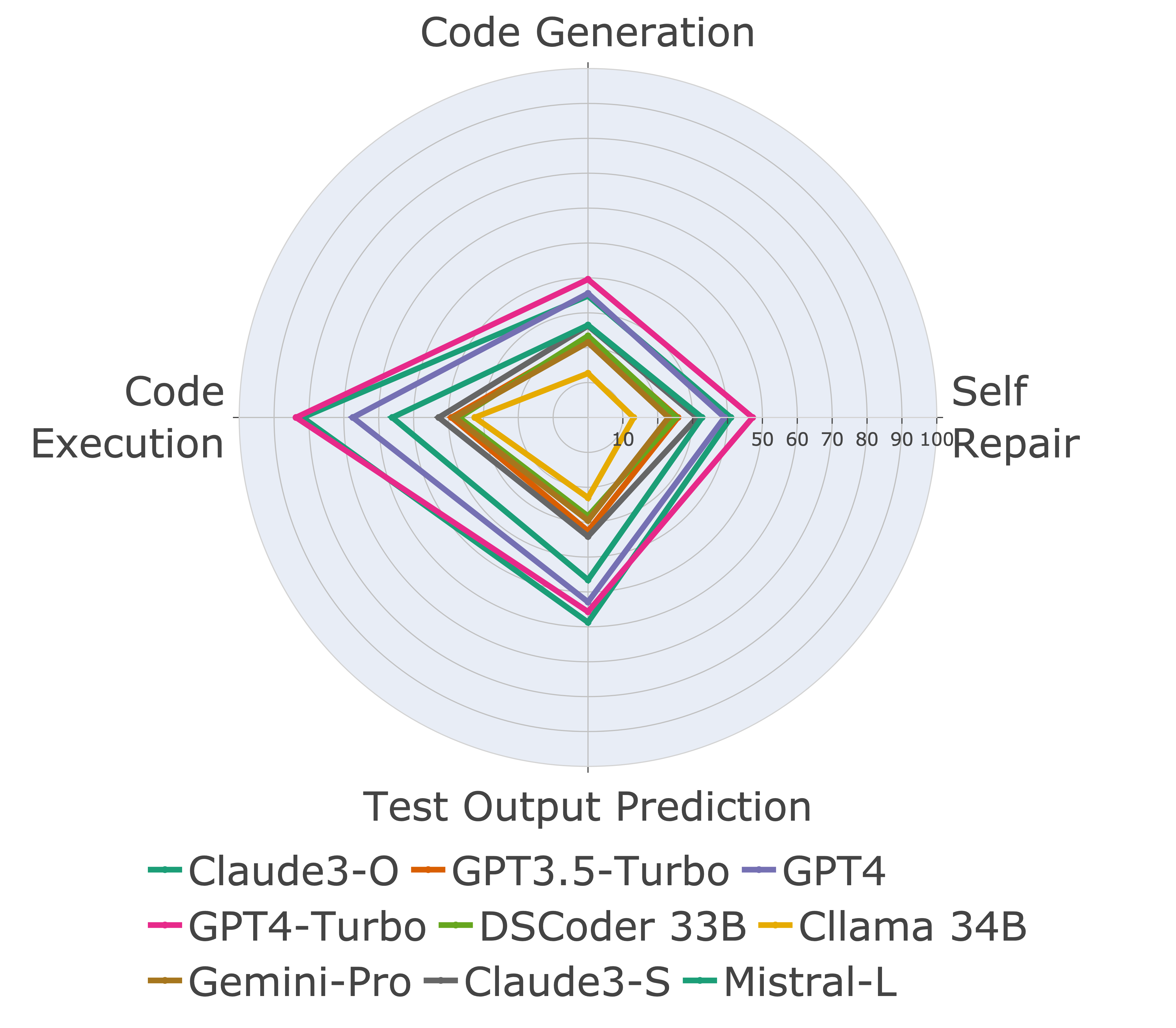
LiveCodeBench evaluates models on a variety of code-related scenarios, such as code generation, self-repair, test output prediction, and code execution. We find that while model performances are correlated across different scenarios, there relative performances and ordering can vary (left figure). For instance, Claude-3-Opus overtakes GPT-4-turbo in the test output prediction scenario, but not in the code generation scenario. Similarly, Mistral-Large performs considerably better on natural language reasoning tasks like test output prediction and code execution.
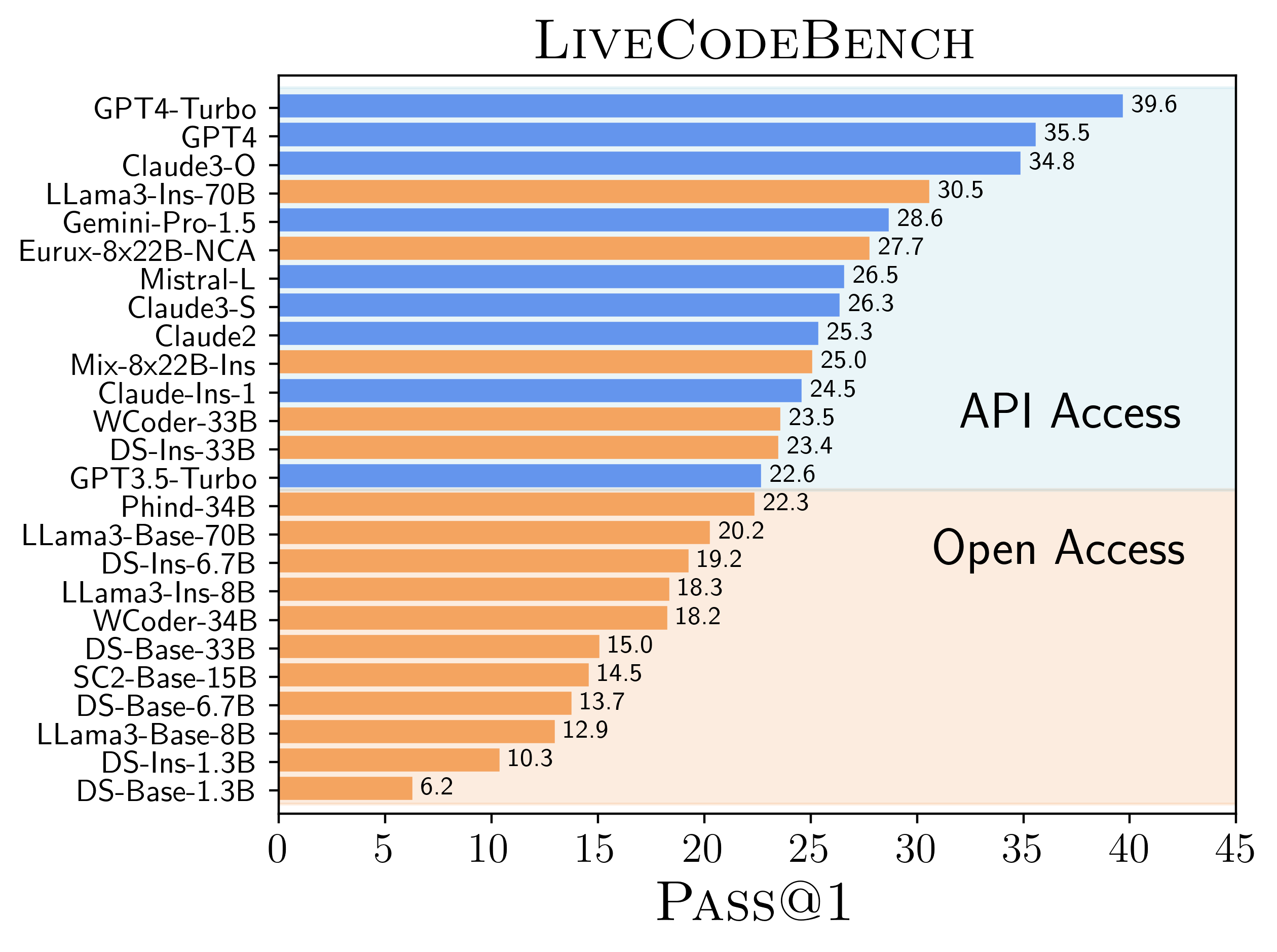
We compare the performance of open access models with closed api-access models on LiveCodeBench and find that generally the closed api-access models outperform the open models. Particularly, the only open models that surpass the barrier are fine-tuned variants of large (30+B parameter) models.
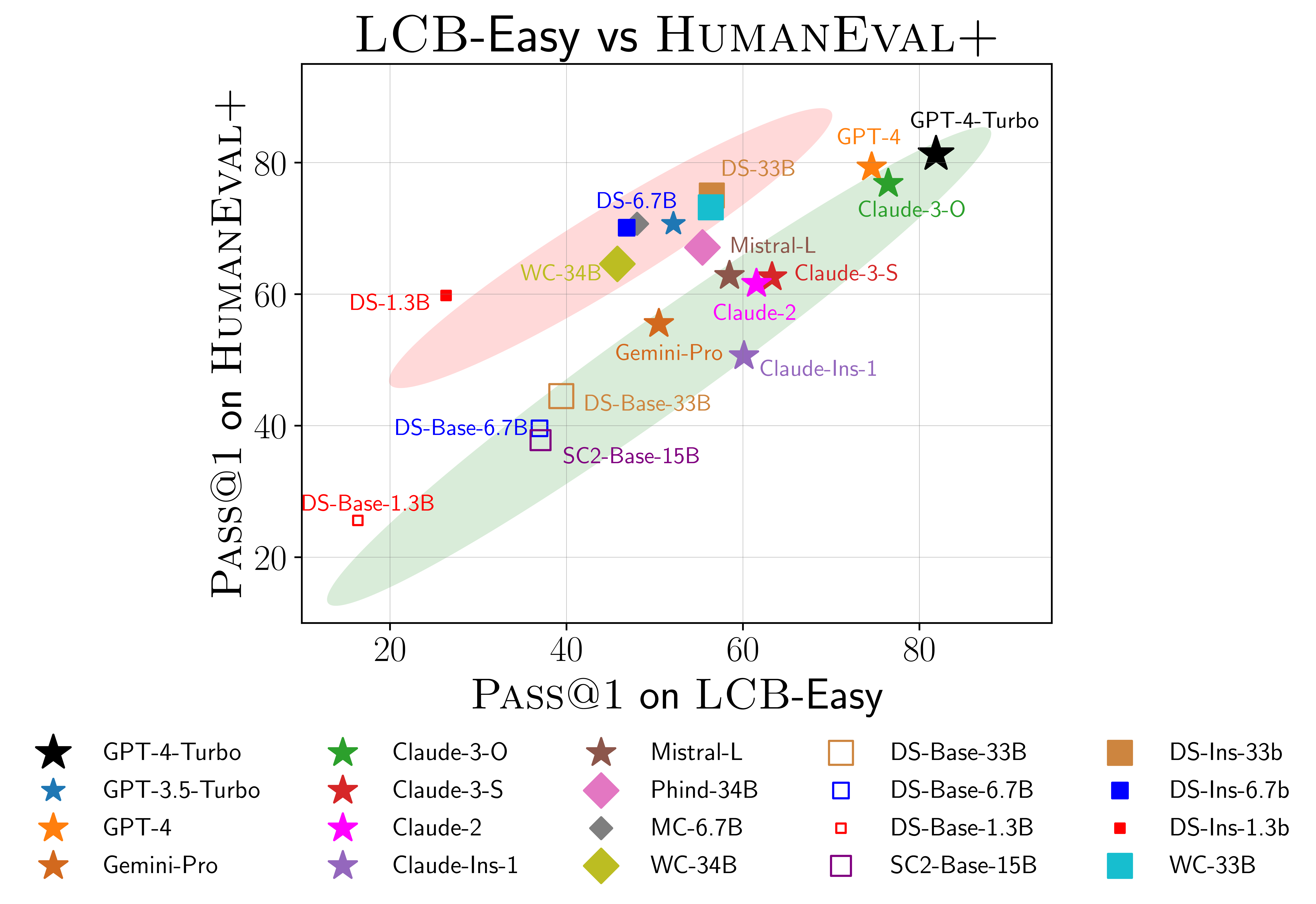
We also find that models that perform well on HumanEval might be overfitting on the benchmark. Particularly, the models are separated into two clusters depicted by the green and red shaded region in the right scatterplot. The models in the green region perform similarly on HumanEval and LCB-Easy, while the models in the red region perform well on HumanEval but lag behind on LCB-Easy. For instance, DS-Ins-1.3B model outperforms Gemini-Pro and Claude-Ins-1 but performs considerably worse on LCB-Easy. Interestingly, the models in the red region are mostly fine-tuned variants of open access models. On the other hand, base models and most of the closed api-access models lie in the green region. This highlights a potential lack of diverse fine-tuning data being employed by the open source community and the need for optimizing models for a broader set of code-related tasks.
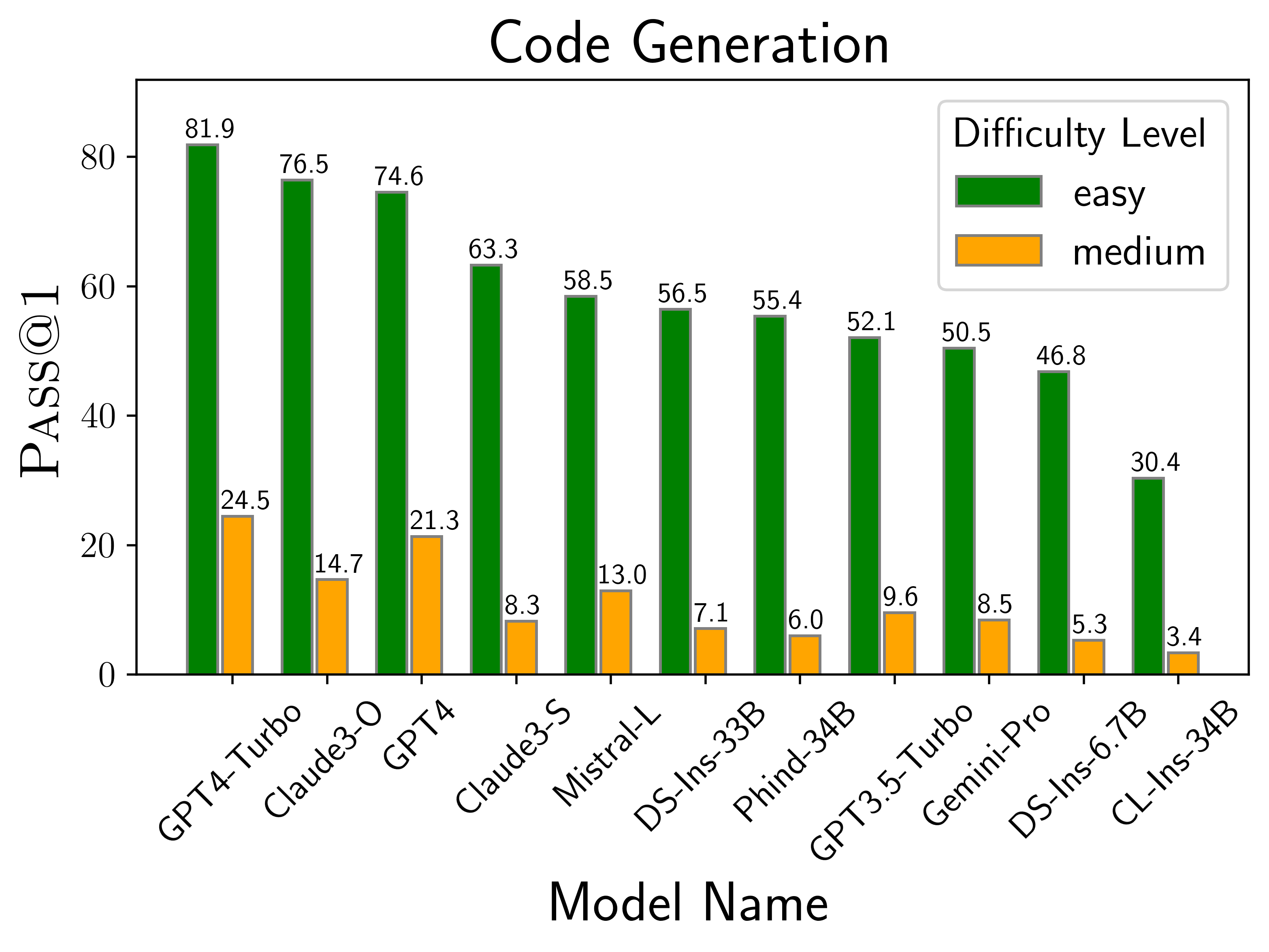
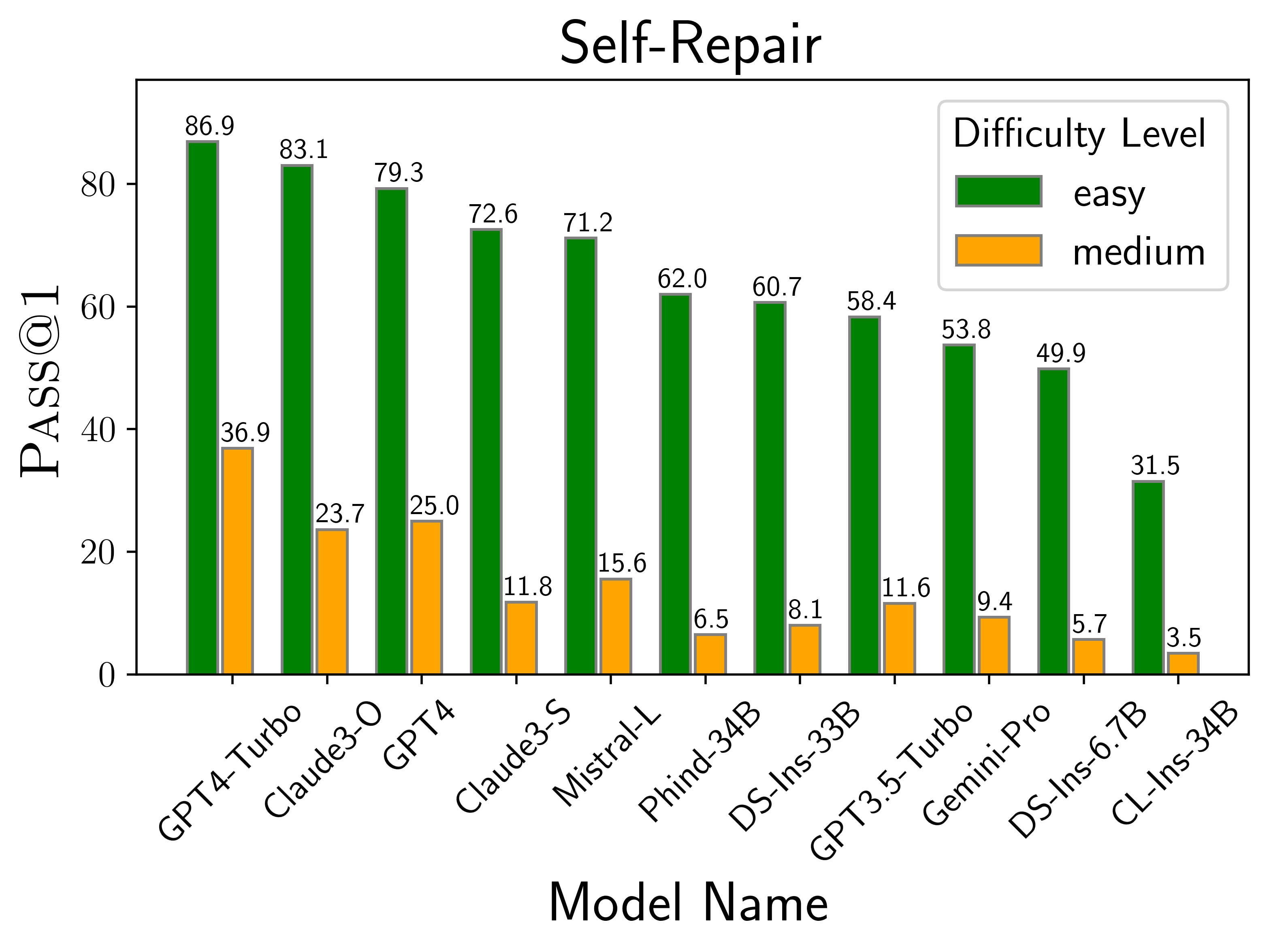
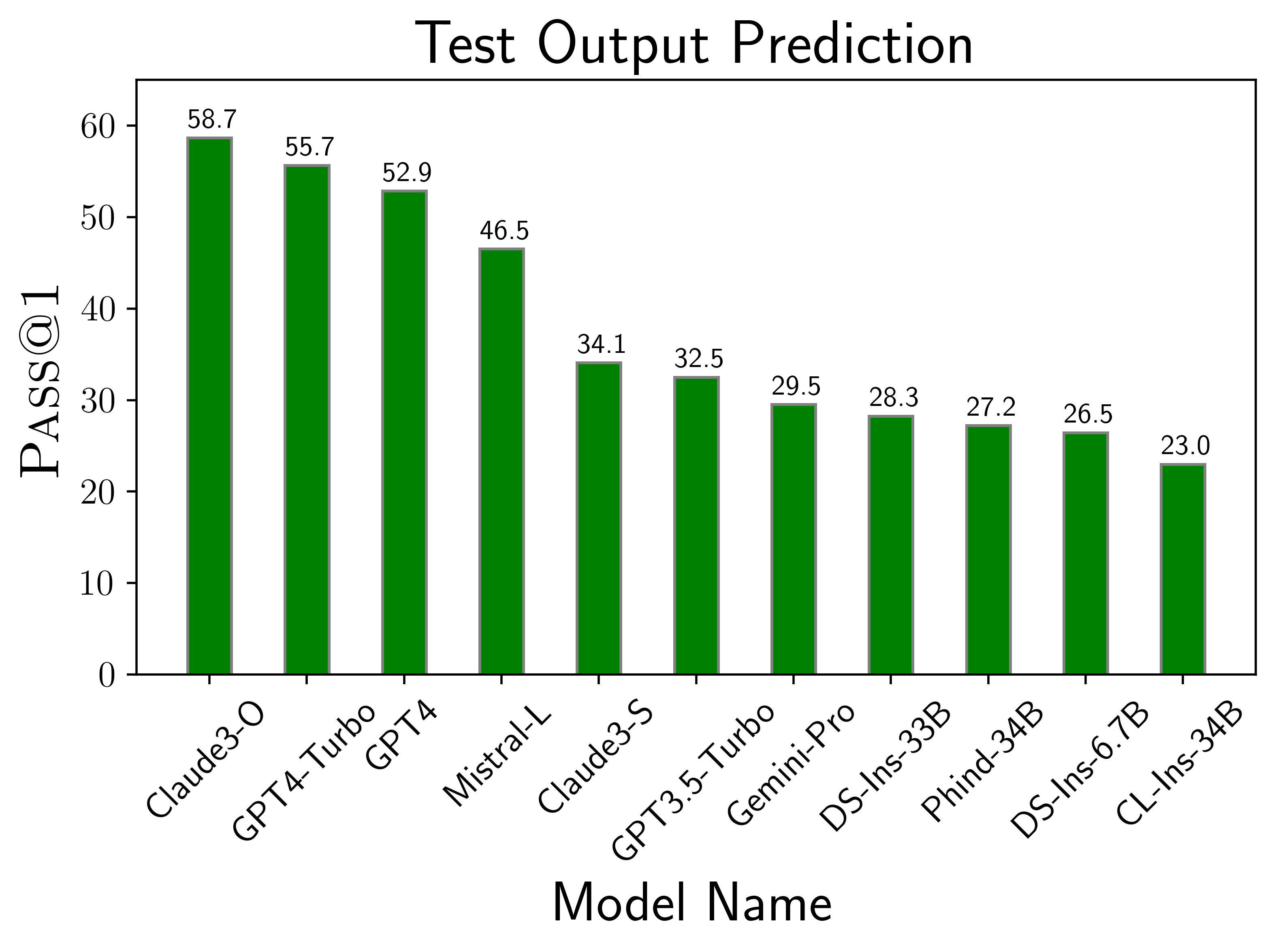
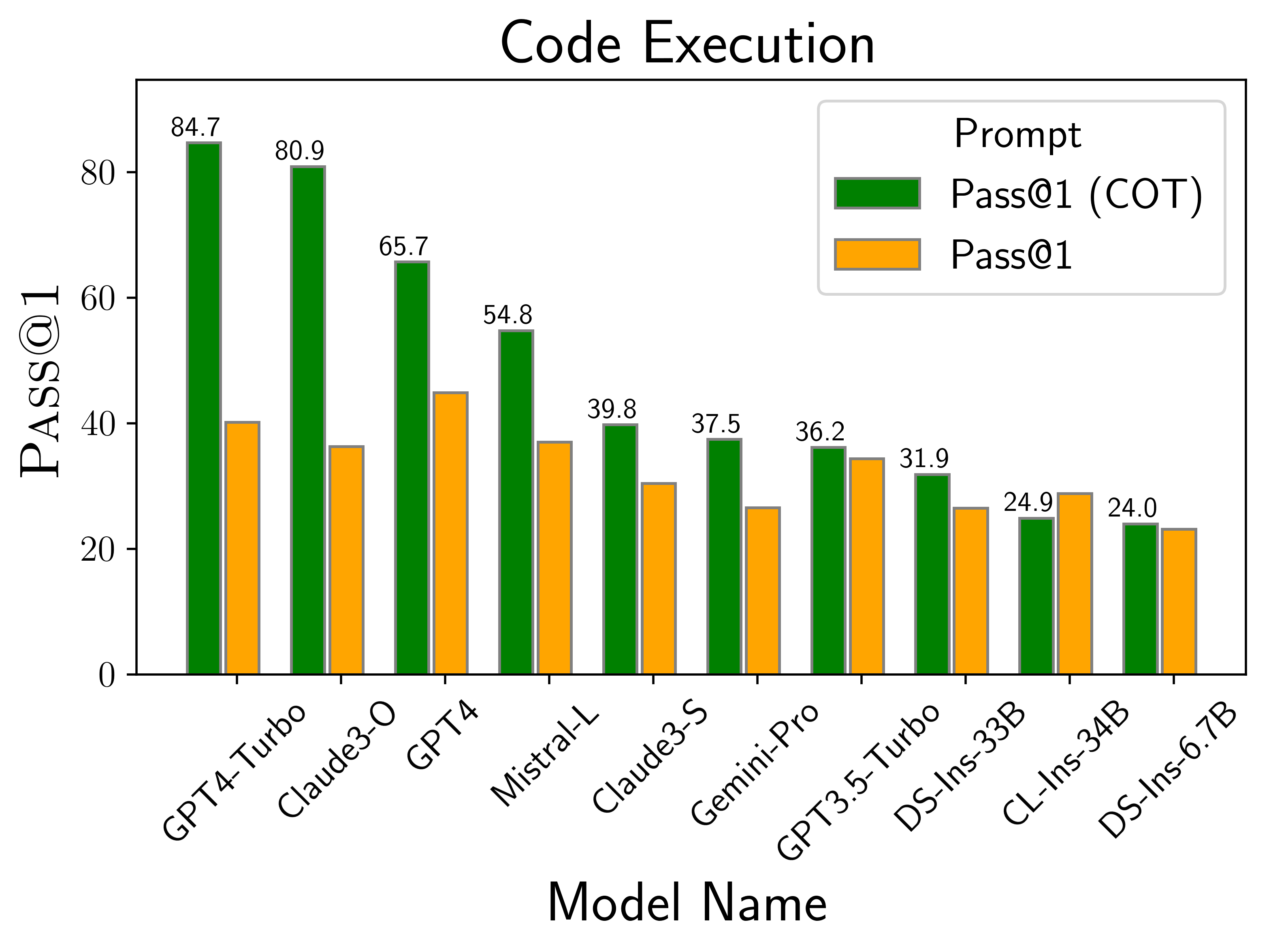
The above plots depict the performance of models on different scenarios considered in LiveCodeBench. We find that GPT-4-turbo and Claude-3-Opus models perform best across different scenarios. Among open source models, DS-Ins-33B and Phind-34B perform the best.
To submit models you can create a pull request on our Github. Particularly, you can copy your model generations folder from `output` to the `submissions` folder and create a pull request. We will review the submission and add the model to the leaderboard accordingly.
@article{jain2024livecodebench,
title={LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code},
author={Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion},
journal={arXiv preprint arXiv:2403.07974},
year={2024}
}